前不久《最强大脑》第四季第一期的舞台上,王峰对阵小度机器人进行了“人机大战”,其中最精彩和有趣的是第一场pk—从小时候照片判别长大后对应的人,而她有个姐姐,这对姐妹恰恰是双胞胎!百度真的这么强吗,可以识别出万分之一的区别?

有没有办法衡量百度到底有多强,带着这个疑问,我搜到了百度已经开放了他的人脸识别sdk。同时作为对比,我选择旷视科技这家公司,因为他们的技术应用在支付宝人脸支付、人脸解锁等场景(https://zhuanlan.zhihu.com/p/21978771)。作为程序员,撸起袖子马上干起来。
还要说明下的是,人脸对比是确认一张照片的人和另一张照片的人的相似度,相似度越高说明两个人越像,越低说明两个人不像。大家常见的就是支付宝里的刷脸支付,它的作用和签名验证、指纹验证(上班手指打卡器)一样,确定你是不是你的问题。而人脸对比和最强大脑里的从小时候照片推算出长大后照片有些不同,但目标是一样的,都是看相似性。通过对比人脸识别中人脸对比的准确性,可以知道谁的算法更加强劲。
- 百度人脸对比sdk入口地址:https://cloud.baidu.com/product/face/compare
- 旷视科技人脸对比入口地址:https://www.faceplusplus.com.cn/face/detect-api.html
分别注册账号,拿到api key和api secret,阅读下示例代码。发现face++的很简单,直接用curl.exe + MS命令行。而百度我选择用python sdk。由于我用的是免费的接口,旷视的调用次数限制未知,而百度的api每天最多1000次,他们都对并发不做保证,如果想要商用并且调用次数很多,考虑买个商用授权吧。同时还要说明,试用版和商用版用的效果是一样的,也就是商用版识别结果会和试用版一样,仅仅是次数限制。
face++对免费api的说明:
- 并发数有上限且不保证并发:由于资源有限,在调用繁忙的情况下,您的请求有可能会受到并发限制。
- Face 存储有上限:每个用户使用免费服务只能创建 1000个 FaceSet,总计最多存储 100 万个人脸。
- 一个用户只能有一个 API Key 使用免费服务,而且该 API Key 不能转为正式 API Key。
1.首先我想到的是对比下双胞胎辨别能力如何
从朱佳雯微博提取了3张正面照片,从朱佳怡提取1张正面图片。
图片来源:
蜜蜂少女队-朱佳雯 http://weibo.com/u/5873198061
http://tva2.sinaimg.cn/crop.0.0.749.749.180/006ptl6Zjw8fa9d1bq3xmj30ku0ktmyd.jpg
http://wx1.sinaimg.cn/mw690/006ptl6Zgy1fc0nme8eapj31ho1zk7wj.jpg
http://wx3.sinaimg.cn/mw690/006ptl6Zgy1fcfsg03fs1j31ho1zkhdv.jpg
蜜蜂少女队-朱佳怡 http://www.weibo.com/u/5873198101
http://tva3.sinaimg.cn/crop.0.0.749.749.180/006ptl7Djw8fa0yk1bwisj30ku0ktmy7.jpg
face++的识别代码,请将“应用的API Key”和“应用的Secret Key”分别替换成申请到的字符串。
|
1 2 3 4 5 6 7 8 9 10 |
set ZJW1=http://tva2.sinaimg.cn/crop.0.0.749.749.180/006ptl6Zjw8fa9d1bq3xmj30ku0ktmyd.jpg set ZJW2=http://wx1.sinaimg.cn/mw690/006ptl6Zgy1fc0nme8eapj31ho1zk7wj.jpg set ZJW3=http://wx3.sinaimg.cn/mw690/006ptl6Zgy1fcfsg03fs1j31ho1zkhdv.jpg set ZJY=http://tva3.sinaimg.cn/crop.0.0.749.749.180/006ptl7Djw8fa0yk1bwisj30ku0ktmy7.jpg curl -X POST "https://api-cn.faceplusplus.com/facepp/v3/compare" -F "api_key=应用的API Key" -F "api_secret=应用的Secret Key" -F "image_url1=%ZJW1%" -F "image_url2=%ZJY%" curl -X POST "https://api-cn.faceplusplus.com/facepp/v3/compare" -F "api_key=应用的API Key" -F "api_secret=应用的Secret Key" -F "image_url1=%ZJW2%" -F "image_url2=%ZJY%" curl -X POST "https://api-cn.faceplusplus.com/facepp/v3/compare" -F "api_key=应用的API Key" -F "api_secret=应用的Secret Key" -F "image_url1=%ZJW3%" -F "image_url2=%ZJY%" curl -X POST "https://api-cn.faceplusplus.com/facepp/v3/compare" -F "api_key=应用的API Key" -F "api_secret=应用的Secret Key" -F "image_url1=%ZJW1%" -F "image_url2=%ZJW2%" curl -X POST "https://api-cn.faceplusplus.com/facepp/v3/compare" -F "api_key=应用的API Key" -F "api_secret=应用的Secret Key" -F "image_url1=%ZJW1%" -F "image_url2=%ZJW3%" curl -X POST "https://api-cn.faceplusplus.com/facepp/v3/compare" -F "api_key=应用的API Key" -F "api_secret=应用的Secret Key" -F "image_url1=%ZJW2%" -F "image_url2=%ZJW3%" |
百度识别代码
安装百度人脸识别包,pip install baidu-aip
百度识别需要使用本地文件,下载她们的照片,依次命名zhujiawen、zhujiawen2、zhujiawen3和zhujiayi,保存到d盘下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 引入人脸识别 SDK from aip import AipFace # 定义常量 APP_ID = '你的 App ID' API_KEY = '你的 API Key' SECRET_KEY = '你的 Secret Key' # 初始化AipFace对象 aipFace = AipFace(APP_ID, API_KEY, SECRET_KEY) # 读取图片 def get_file_content(filePath): with open(filePath, 'rb') as fp: return fp.read() aipFace.match([get_file_content('d:/zhujiawen.jpg'),get_file_content('d:/zhujiayi.jpg'),]) aipFace.match([get_file_content('d:/zhujiawen2.jpg'),get_file_content('d:/zhujiayi.jpg'),]) aipFace.match([get_file_content('d:/zhujiawen3.jpg'),get_file_content('d:/zhujiayi.jpg'),]) aipFace.match([get_file_content('d:/zhujiawen.jpg'),get_file_content('d:/zhujiawen2.jpg'),]) aipFace.match([get_file_content('d:/zhujiawen.jpg'),get_file_content('d:/zhujiawen3.jpg'),]) aipFace.match([get_file_content('d:/zhujiawen2.jpg'),get_file_content('d:/zhujiawen3.jpg'),]) |
图片如下(前三章朱佳雯,后一张朱佳怡):
对比结果如下(数值越高越相似):
| 表1 | 人脸对比结果 | |||
| 序号 | 图片1 | 图片2 | face++ | 百度 |
| 1 | 朱佳雯1 | 朱佳怡 | 88.804 | 93.915 |
| 2 | 朱佳雯2 | 朱佳怡 | 84.242 | 94.210 |
| 3 | 朱佳雯3 | 朱佳怡 | 79.859 | 93.574 |
| 4 | 朱佳雯1 | 朱佳雯2 | 84.716 | 93.172 |
| 5 | 朱佳雯1 | 朱佳雯3 | 87.825 | 92.108 |
| 6 | 朱佳雯2 | 朱佳雯3 | 83.453 | 92.042 |
这个是百度运行结果,可以参考下:
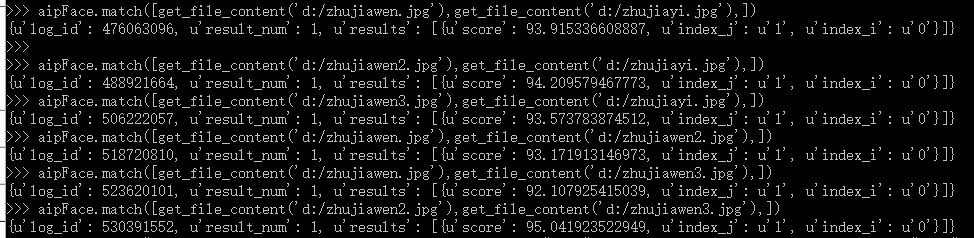
我们观察数据,分析下:
1)序号1、序号2的数值都比序号6大,这意味着双胞胎的相似度有时高过自己与自己的相似度。这说明,最强大脑中,小度可能真的是运气好,蒙对了!
2)百度的数据比较集中,在92~95之间,而face++数据在79~89之间。这说明百度的算法可能比较准确。(双胞胎确实像啊,怎么face++范围波动那么大?)
3)观察最大值,face++在1(人不同)和5(同一个人)时数值最大,百度在1(人不同)和2(人不同)数值最大。face++比百度稍微好些。
4)观察最小值,face++序号3(不同人)最小,百度序号6最小(同一人)。face++比百度好。
对比双胞胎,双方确实都有问题。要说谁好一些,我投face++一票。
2.可能你说上一回合,各有错误,而每张照片差别太大(清晰度、时间、光照、妆容都不一样)。那么同一个人在同一时间段的照片分别对比(人脸表情、朝向不同),看看相似性是不是应该很高。
这次换王珞丹,从她的微博弄下5张图,分别用第1张与后4张进行对比:
王珞丹
http://ww2.sinaimg.cn/mw1024/49393842jw1f8wne2olizj22as3g6u0x.jpg
http://ww1.sinaimg.cn/mw1024/49393842jw1f8wnejo9tyj22as3g6u0y.jpg
http://ww4.sinaimg.cn/mw1024/49393842jw1f8wne9yic3j22as3g6qv6.jpg
http://ww3.sinaimg.cn/mw1024/49393842jw1f8wndxibndj22as3g6qv5.jpg
http://ww3.sinaimg.cn/mw1024/49393842jw1f8wnee6krdj22as3g6qv6.jpg

对比代码:
face++的
|
1 2 3 4 5 6 7 8 9 |
set WLD1=http://ww2.sinaimg.cn/mw1024/49393842jw1f8wne2olizj22as3g6u0x.jpg set WLD2=http://ww1.sinaimg.cn/mw1024/49393842jw1f8wnejo9tyj22as3g6u0y.jpg set WLD3=http://ww4.sinaimg.cn/mw1024/49393842jw1f8wne9yic3j22as3g6qv6.jpg set WLD4=http://ww3.sinaimg.cn/mw1024/49393842jw1f8wndxibndj22as3g6qv5.jpg set WLD5=http://ww3.sinaimg.cn/mw1024/49393842jw1f8wnee6krdj22as3g6qv6.jpg curl -X POST "https://api-cn.faceplusplus.com/facepp/v3/compare" -F "api_key=应用的API Key" -F "api_secret=应用的Secret Key" -F "image_url1=%WLD1%" -F "image_url2=%WLD2%" curl -X POST "https://api-cn.faceplusplus.com/facepp/v3/compare" -F "api_key=应用的API Key" -F "api_secret=应用的Secret Key" -F "image_url1=%WLD1%" -F "image_url2=%WLD3%" curl -X POST "https://api-cn.faceplusplus.com/facepp/v3/compare" -F "api_key=应用的API Key" -F "api_secret=应用的Secret Key" -F "image_url1=%WLD1%" -F "image_url2=%WLD4%" curl -X POST "https://api-cn.faceplusplus.com/facepp/v3/compare" -F "api_key=应用的API Key" -F "api_secret=应用的Secret Key" -F "image_url1=%WLD1%" -F "image_url2=%WLD5%" |
百度的(还是一次下载图片,保存为wangluodan1、wangluodan2、wangluodan3、wangluodan4、wangluodan5)
|
1 2 3 4 |
aipFace.match([get_file_content('d:/wangluodan1.jpg'),get_file_content('d:/wangluodan2.jpg'),]) aipFace.match([get_file_content('d:/wangluodan1.jpg'),get_file_content('d:/wangluodan3.jpg'),]) aipFace.match([get_file_content('d:/wangluodan1.jpg'),get_file_content('d:/wangluodan4.jpg'),]) aipFace.match([get_file_content('d:/wangluodan1.jpg'),get_file_content('d:/wangluodan5.jpg'),]) |
对比结果如下(数值越高越相似):
| 表2 | 人脸对比结果 | |||
| 序号 | 图片1 | 图片2 | face++ | 百度 |
| 1 | 王珞丹1 | 王珞丹2 | 88.973 | 95.826 |
| 2 | 王珞丹1 | 王珞丹3 | 94.752 | 98.096 |
| 3 | 王珞丹1 | 王珞丹4 | 81.722 | 93.068 |
| 4 | 王珞丹1 | 王珞丹5 | 80.724 | 94.447 |
果不其然,face++的相似度范围来去太大,而百度依旧十分稳定!这一回合百度完胜。可以看到face++在人脸发生很大的旋转、表情发生变化时,数值波动增大,识别效果不如百度。这一回合毋庸置疑,我投百度一票。
最后在看一下不同的人的对比:
| 表3 | 人脸对比结果 | |||
| 序号 | 图片1 | 图片2 | face++ | 百度 |
| 1 | 朱佳雯1 | 王珞丹1 | 59.221 | 53.006 |
再一次看到对于不同的人,百度的相似度更低。百度能在同样的人的对比中,相似度更高,而在不同人对比中,相似度更低,这一回合我投百度一票。最终还是百度更强,说明百度的人脸识别应该是国内最强。
- 文章仅从少量数据分析,如果要更强说服力,需要拿更多的图片对比。
- 文章可以分享,谢绝转载。
- 文中图片皆来自互联网,侵权立删。

![[转]微软展示高精准度的手部追踪技术-李逍遥说说](http://brightguo.com/wp-content/uploads/2014/10/hand.jpg)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}