这两个月业余时间在写一个本地运行的 AI 视频生成工具,从最初两天攒出来的丑陋原型,到现在能基本自动跑完整条流水线。过程里踩了不少坑,记录一下,也顺便求点反馈。
起因
今年 3 月看到同事在做一种很「拼装」的内容流程:用扣子生成播客语音、豆包生成图片,再手动丢进剪映拼字幕导出。内容和图都是 AI 出的,他只负责最后合成。我当时的第一反应不是「这能涨粉」,而是「这几步明明可以全自动,为什么还要人肉拼」。于是动了自己写一个的念头。
第一版(两天)
4 月底试了下新出的 DeepSeek V4 的 flash 模型,速度和价格都到了我能接受的程度,就趁着这股劲把脑子里的流程实现了一版。第一版很糙,但跑通了「输入一段文字 → 自动出成片」这条主线。
整条流水线现在大概是这样:
- 把一段几千字的文稿输入软件;
- 调 DeepSeek,按预设的频道设定生成对话脚本 + 配图提示词;
- 调豆包播客模型生成多角色对话语音;
- 调 Seedream 按提示词出图;
- 用 ffmpeg 把音频、图片、字幕合成 MP4。
中间的字幕对齐、多角色音色分配、图片和台词的时间轴对应,是最磨人的几块。
踩过的坑(挑几个)
- 音字对齐:配音时长和字幕、画面切换怎么对齐,最早全靠估,效果很飘,后来才老老实实按音频时间轴去切。
- ffmpeg 合成:滤镜链、分辨率、编码参数一堆隐性坑,子进程报错信息还经常被吞,调试体验很差。
- 成本控制:一开始没注意 token 用量,跑几条就肉疼;现在一条 5 分钟左右的片子模型成本压到一两块。
- 本地化:密钥、素材、产物我都坚持只存本地,不上云,这样自己用着也踏实,但也因此放弃了一些云端能做的优化。
目前状态 / 还很不足的地方
现在能基本「点一下、等一会」跑完一条片子,但远谈不上完善:异常恢复、长文稿的稳定性、画面风格的可控性都还在改。我基本每天根据自己和试用者的反馈在迭代。另外目前只有 Windows 版,macOS 大概要往后排到下个月才能动。这个是软件当前形态:
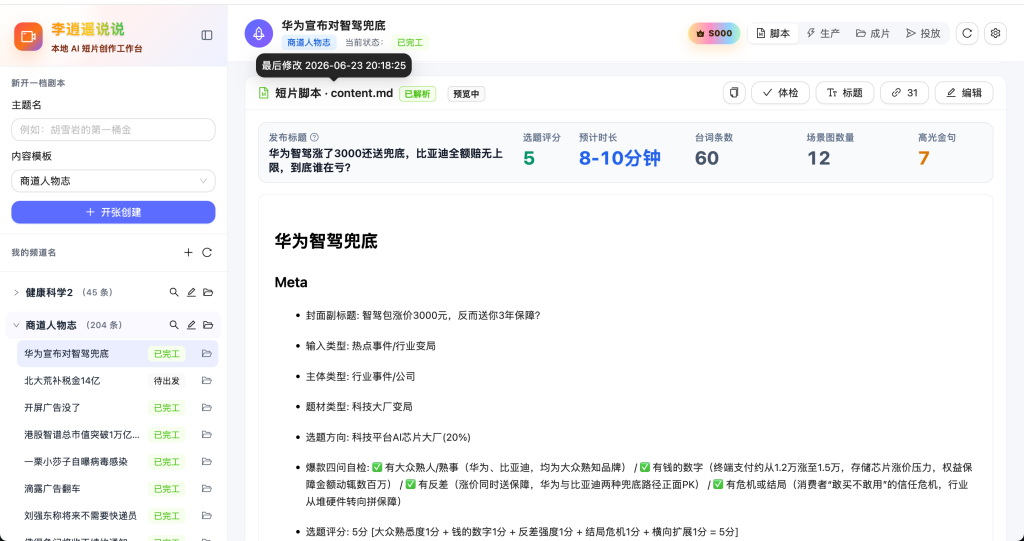
想求点反馈
主要想问问做过类似东西的朋友:
- 音视频对齐这块有没有更省事的方案(除了硬切时间轴)?
- ffmpeg 合成这种重子进程的场景,你们怎么做错误捕获和重试的?
- 激活授权我现在用的是机器码 + 非对称密钥,有没有更轻量又不容易被破的思路?
如果想直接看看长什么样,我整理了文档和下载:https://avm.brightguo.com。能给点拍砖意见就更感激了。







