本来想着花半天时间为自己的公众号“绝对影迷”第二版的需求,爬下豆瓣电影数据。在知乎看到不少大神说自己爬豆瓣电影有多快~于是我周六开始坑爹的爬豆瓣电影数据之旅~
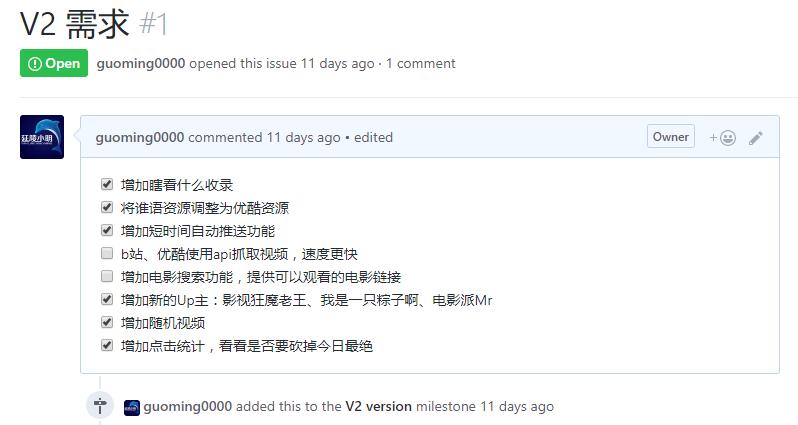
首先,花了一二个小时定义好数据库结构(大写开头大多是自己定义的,非豆瓣数据),写好sqlite3数据库生成、插入、更新的函数。
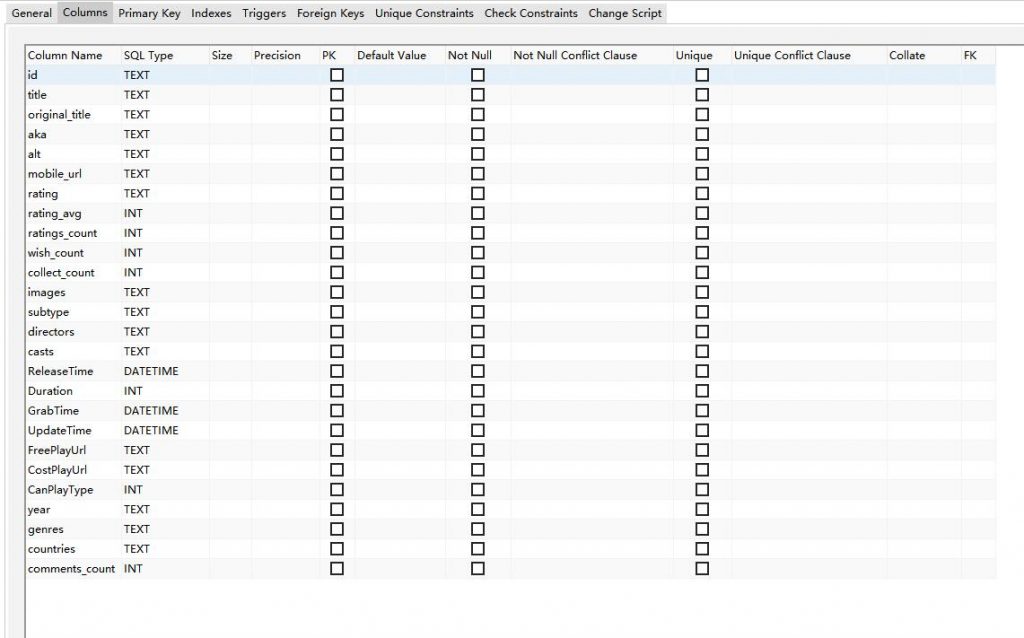
然后使用requests爬取tag页面,有别人代码可以参照,也很顺利,程序跑起来,依旧是凌晨二三点,我就睡了。第二天一早起来,发现怕了2W来条数据(主要是上图中的id数据,其他数据得调用另一个接口才能爬),发现ip被封了~这样,告知我得需要代理爬取才行。
同时发现豆瓣有api可以直接搜到所有标签下的电影(忽略total字段那个最大是200,那个是骗人用的,当然不可能就200个结果呀~)
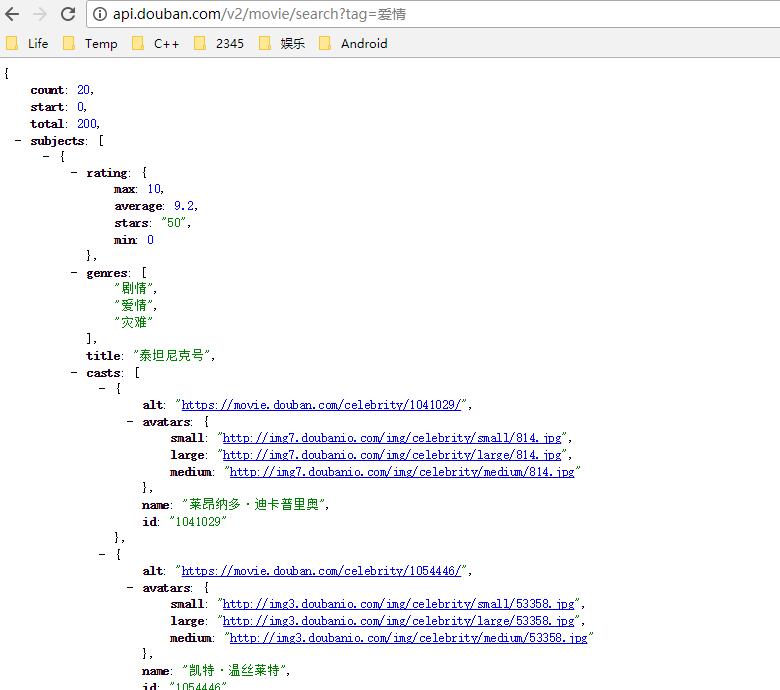
很快把解析网页的改成解析api函数的方法,跑起来后,过一会ip又被封了,同时我发现感觉好慢啊!
果断上代理ip和多线程功能啊!代理ip参照网上简单爬取的方法,弄了二三个小时发现他的代码有三四处bug,坑死我了,囧~google后解决,发现程序才启动几秒,很多ip就被封了。ok,查阅各种可能解释,上random的请求头(fake_useragent库),cookie记得保存,失效后cookie记得更新。请求头、代理ip、cookie需要三位一体,要变一起变,不变就别瞎变,不然瞬间被封,囧~
还有网上说的换bid之类的方法,没鸟用啊,囧~
一直到现在,速度是上去了,但是已经俨然超过单ip每小时爬取的限制。那么普通搞代理ip的数量远远不够用啊,得再搞个线程专门爬代理ip,爬到后丢给豆瓣爬虫用,不合适的ip设置为失效,得有代理ip爬取、更新策略。当然,还有就是放慢速度爬,太快扯着蛋。同时还要弄一个爬取状态存储,因为搞不好所有ip都被封,或者运行时间太长,又要重复之前爬过的地址。
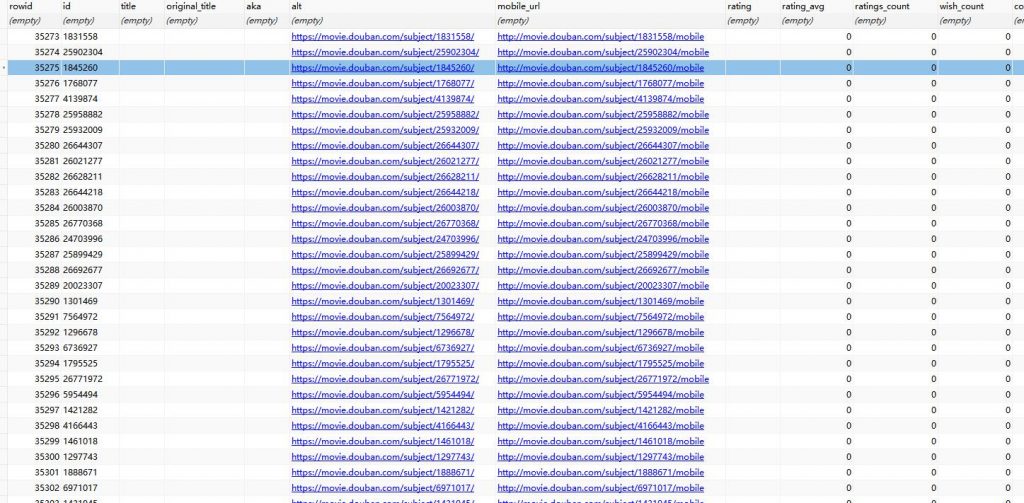
豆瓣确实厉害,毕竟是老牌的网站。目前才爬到了3W条目信息(就一个id信息),后面还需要优化代码,继续爬才有可能爬下去。搞爬虫不容易,因为你慢慢调试时,不会发现这样会被封ip。只有跑起来,才能发现被封了,然后只能一边改一边揣测(YY瞎想)他可能怎么发现我的呢~
同时,我也在想,自己V2的需求中关于api的,优酷的频率限制我知道(好运的是前几年就申请到了他们的普通版的key),由于爬得页面不多,可以做到分钟内甚至10秒内抓取到最新的视频。但是B站公开的api,每分钟能调用几次就不知道了~这个得不断尝试,看看多大的频率他会封ip才知道了~现在的网站,大多不让申请open api的key了,也就是不让大家太容易爬数据鸟~





![[转]selenium设置chrome和phantomjs的请求头信息-李逍遥说说](https://www.urlteam.org/wp-content/uploads/2017/02/996148-20161203114330787-1216998587.png)



